How can you trust something that you're really not aware of, but yet controls more and more of how we see and do things?
The role of algorithms can’t be understated in the technological world we now live in. For example, they help dictate the search results and ads we get online and help us get from place to place. Plus, businesses and governments rely on them more than ever to help make critical decisions.

Kate-Smith-Miles
Professor Kate Smith-Miles
That's where Professor Kate Smith-Miles comes in. She's developed a new online tool that improves the way we "stress-test" algorithms.
"Trust builds when an algorithm gives the ‘right answer' to enough convincing test cases. Not just the easy, obvious ones. But challenging ones, realistic ones, and those covering enough diversity that we are confident there is no bias," said Kate, a Professor of Mathematics at The University of Melbourne and a Chief Investigator for the ARC Centre of Excellence for Mathematical and Statistical Frontiers (ACEMS).
Kate's story that she wrote for The Conversation
Until now, though, that really hasn't happened. Instead, Kate says most algorithms are merely tested on a set of benchmark test cases that are not scrutinised for these challenging properties. Also, the results of these tests on algorithms merely show how they perform ‘on average'.
This is especially true in the academic peer-review process.
"If a new algorithm is superior on these benchmarks on average, it is usually publishable. If an algorithm is not competitive with existing algorithms, it is either hidden away or some new test examples are presented where the algorithm is superior," said Kate.
"It's the computer science version of medical researchers failing to publish the full results of clinical trials."
All algorithms have weaknesses, or warts, as Kate likes to call them. She says it's extremely important to show where an algorithm will work well, and more importantly, where it could be unreliable.
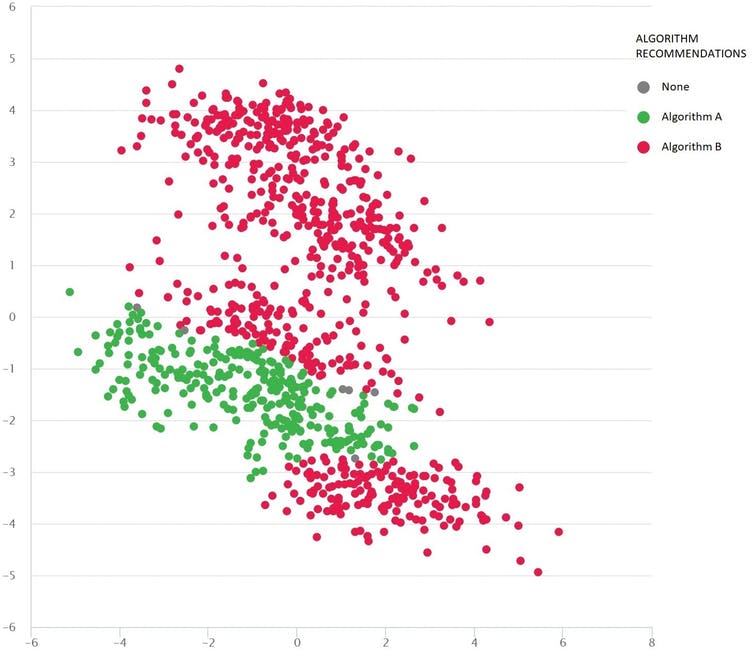
conv-instance-space.jpg
A Google-maps-type problem with diverse test scenarios as dots: Algorithm B (red) is best on average, but Algorithm A (green) is better in many cases. Source: MATILDA
To help researchers do that, Kate and her team have launched a web resource. It's called MATILDA, which stands for the Melbourne Algorithm Test Instance Library with Data Analytics.
What's in a name? Fun facts about why this project is called MATILDA
MATILDA can show the objective strengths and weaknesses of an algorithm through powerful visualisations of a comprehensive 2D test "instance space".
"These instance spaces are filled with carefully generated test examples to augment benchmark datasets, and cover every nook and cranny of the space in which the algorithm could operate: be that working out when it is safe for a plane to land, or ensuring cancer diagnosis is accurate. They reveal which algorithms should be used when, and why," said Kate.
Kate hopes her ’instance space analysis’ will soon replace the standard ‘on average' reporting, now that the tools are available to support a more insightful approach.
The MATILDA project was funded by the Australian Research Council under the Australian Laureate Fellowship scheme awarded to Kate in 2014.